Multimodal Image Synthesis and Editing:
The Generative AI Era
Fangneng Zhan1,2,
Yingchen Yu2,
Rongliang Wu2,
Jiahui Zhang2,
Shijian Lu2,
Lingjie Liu1,
Adam Kortylewski1,
Christian Theobalt1,
Eric Xing3,4
1Max Planck Institute for Informatics, 2Nanyang Technological University
3Carnegie Mellon University, 4Mohamed bin Zayed University of AI



Abstract
As information exists in various modalities in real world, effective interaction and fusion among multimodal information plays a key role for the creation and perception of multimodal data in computer vision and deep learning research. With the prevalence of generative AI models, multimodal image synthesis and editing has become a hot research topic in recent years. Instead of providing explicit guidance for network training, multimodal guidance offers intuitive and flexible means for image synthesis and editing. On the other hand, this field is also facing several challenges in alignment of multimodal features, synthesis of high-resolution images, faithful evaluation metrics, etc. This survey comprehensively contextualizes the advance of the recent multimodal image synthesis and editing and formulate taxonomies according to data modalities and model types. The survey starts with an introduction to different guidance modalities in image synthesis and editing, and then describes multimodal image synthesis and editing approaches extensively according to their model types. After that, it describes benchmark datasets and evaluation metrics as well as corresponding experimental results. Finally, it provides insights about the current research challenges and possible directions for future research.
Gallery
Combination of different guidance types

Methods
Overview
1. NeRF-based Methods
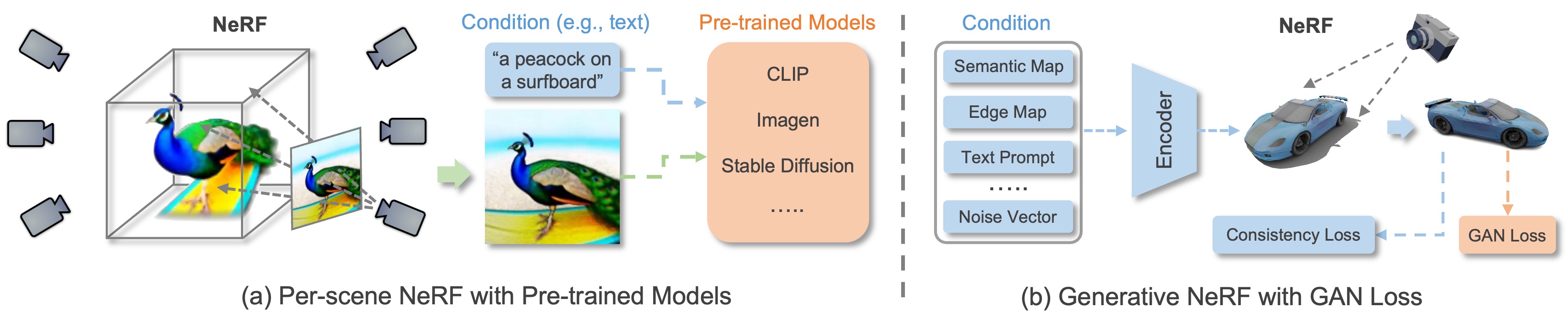
With the recent advance of neural rendering, especially Neural Radiance Fields (NeRF), 3D-aware image synthesis and editing have attracted increasing attention from the community. Distinct from synthesis and editing on 2D images, 3D-aware MISE poses a bigger challenge thanks to the lack of multi-view data and requirement of multi-view consistency during synthesis and editing. As a remedy, pre-trained 2D foundation models (e.g., CLIP and Stable Diffusion) can be employed to drive the NeRF optimization for view synthesis and editing. Besides, generative models like GAN and diffusion models can be combined with NeRF to train 3D-aware generative models on 2D images, where MISE can be performed by developing conditional NeRFs or inverting NeRFs.
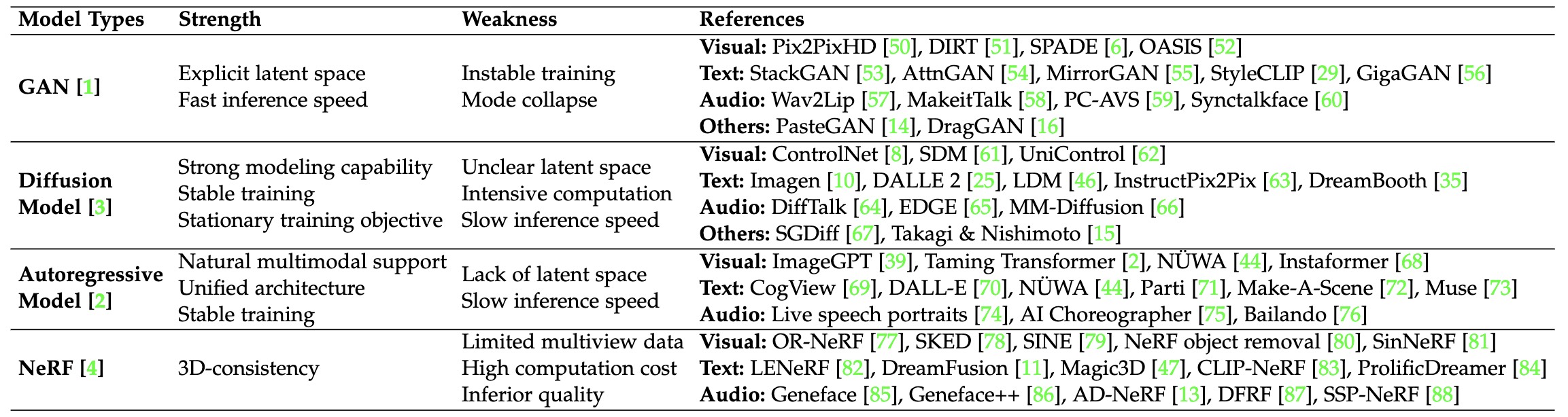
2. GAN & Diffusion-based Methods
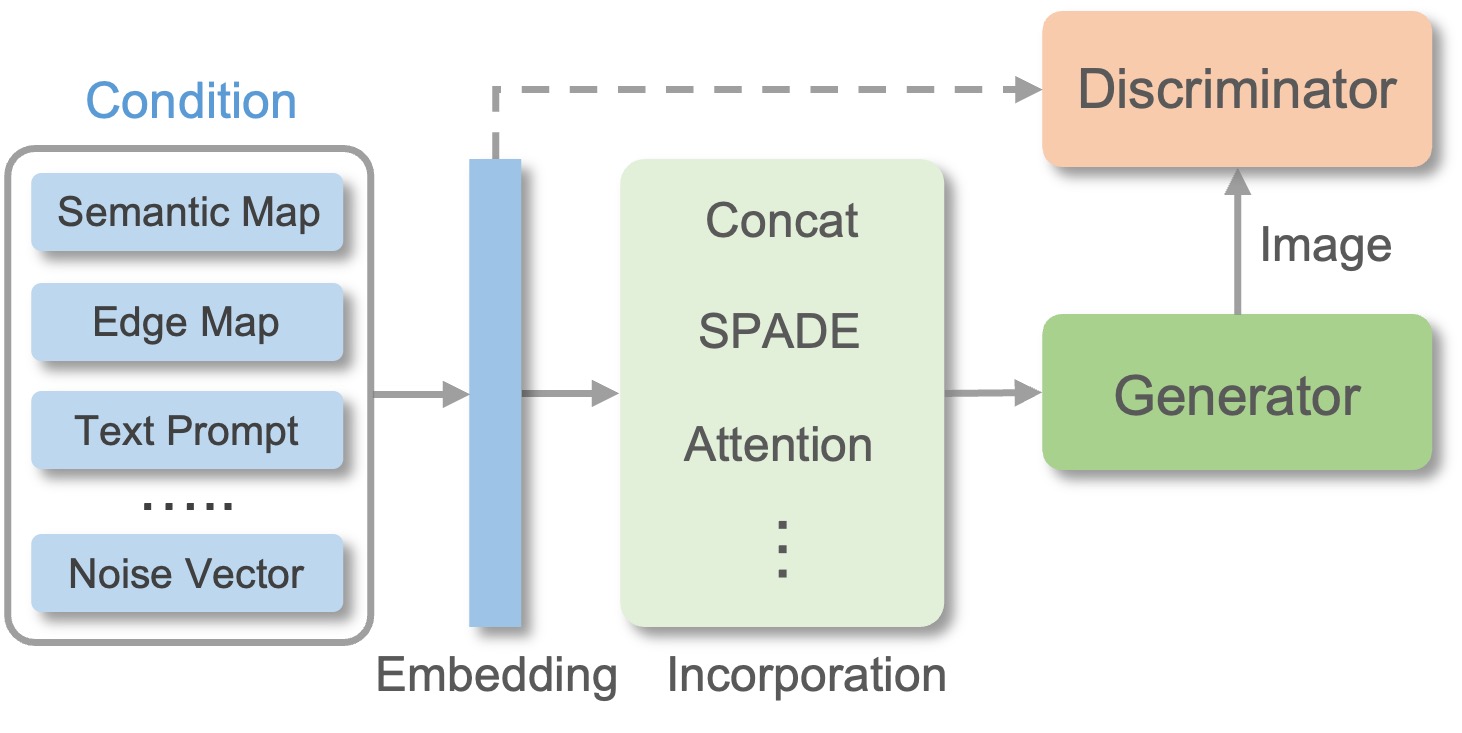
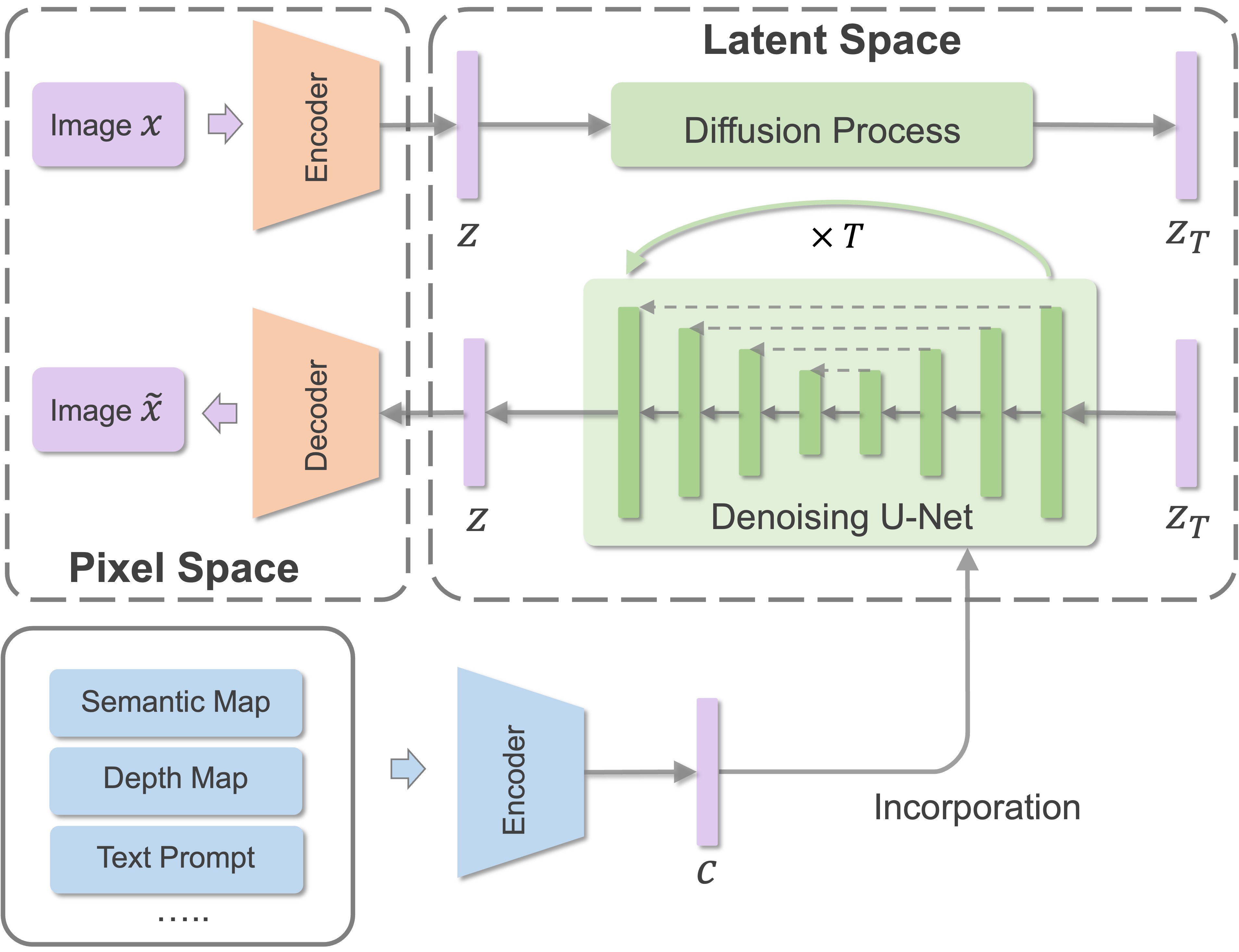
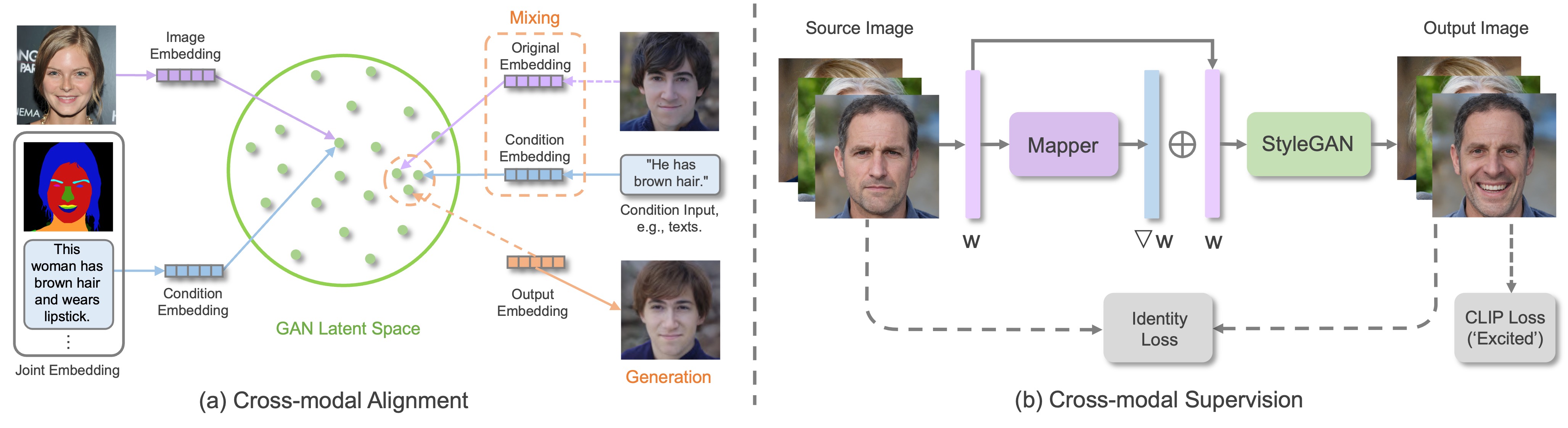
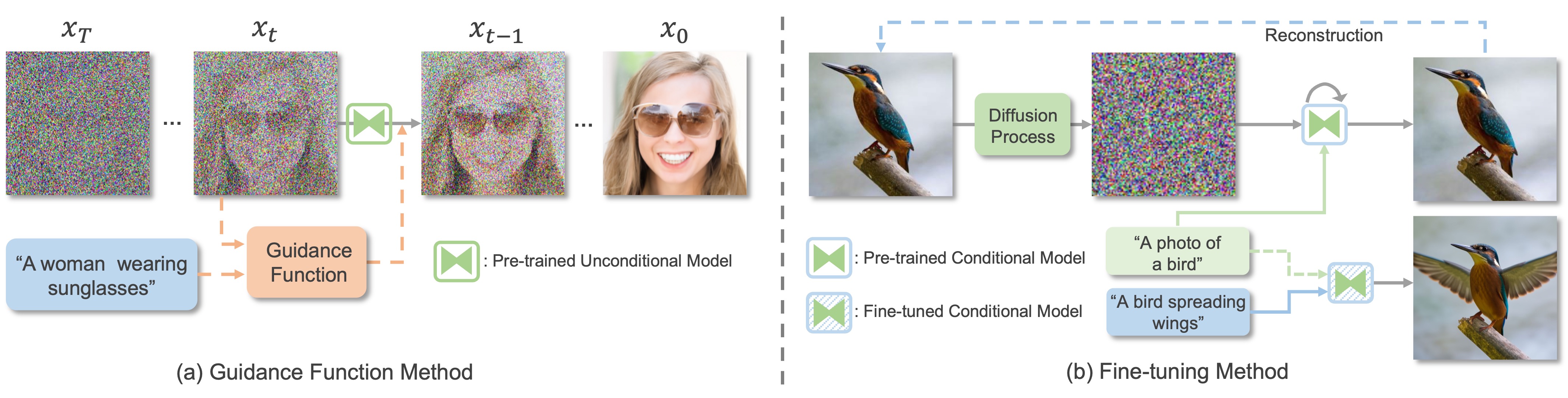
The research of multimodal image synthesis is then significantly advanced with the prosperity of Generative Adversarial Networks (GANs) and diffusion models. Originating from the Conditional GANs (CGANs), a bunch of GANs and diffusion models have been developed to synthesize images from various multimodal signals, by incorporating the multimodal guidance to condition the generation process. This conditional generation paradigm is relatively straight-forward and is widely adopted in SOTA methods to yield unprecedented generation performance. On the other hand, developing conditional model require a cumbersome training process which usually involves high computational cost. Thus, another line of research refers to pre-trained models for MISE, which can be achieved by manipulation in the GAN latent space via inversion, applying guidance functions to diffusion process or adapting the latent space & embedding of diffusion models.
3. Autoregressive Methods
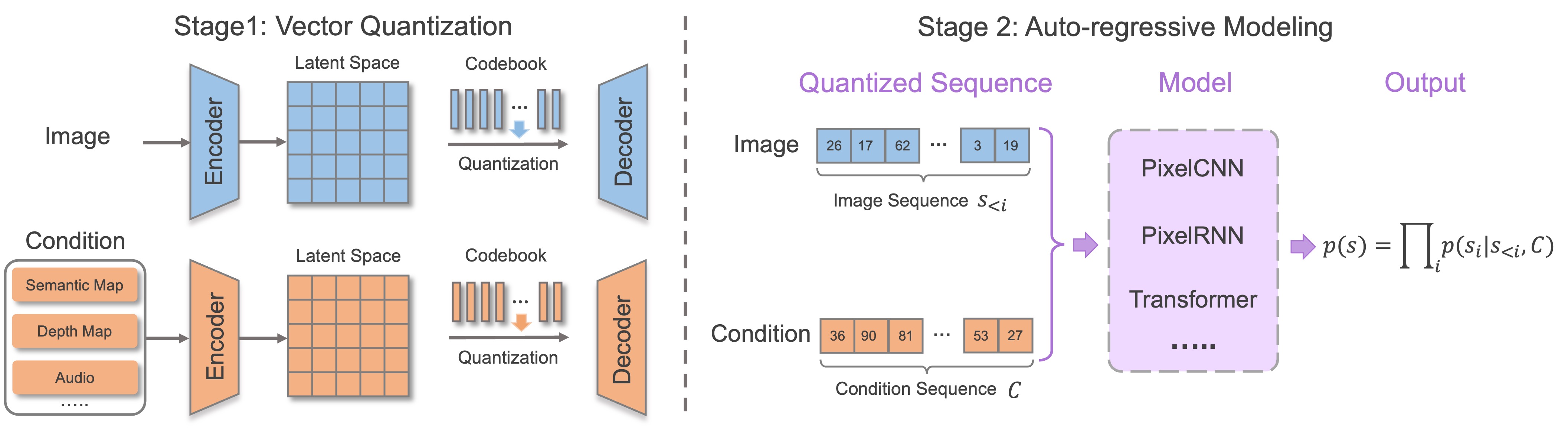
Currently, a CNN architecture is still widely adopted in GANs and diffusion models, which hinders them from supporting diverse multimodal input in a unified manner. On the other hand, with the prevalence of Transformer model which naturally allows various multimodal input, impressive improvements have been made in the generation of different modality data, such as language, image, and audio. These recent advances fueled by Transformer suggest a possible route for autoregressive models in MISE by accommodating the long-range dependency of sequences. Notably, both multimodal guidance and images can be represented in a common form of discrete tokens. For instance, texts can be naturally denoted by token sequence; audio and visual guidance including images can be represented as token sequences. With such unified discrete representation, the correlation between multimodal guidance and images can be well accommodated via Transformer-based autoregressive models which have pushed the boundary of MISE significantly.
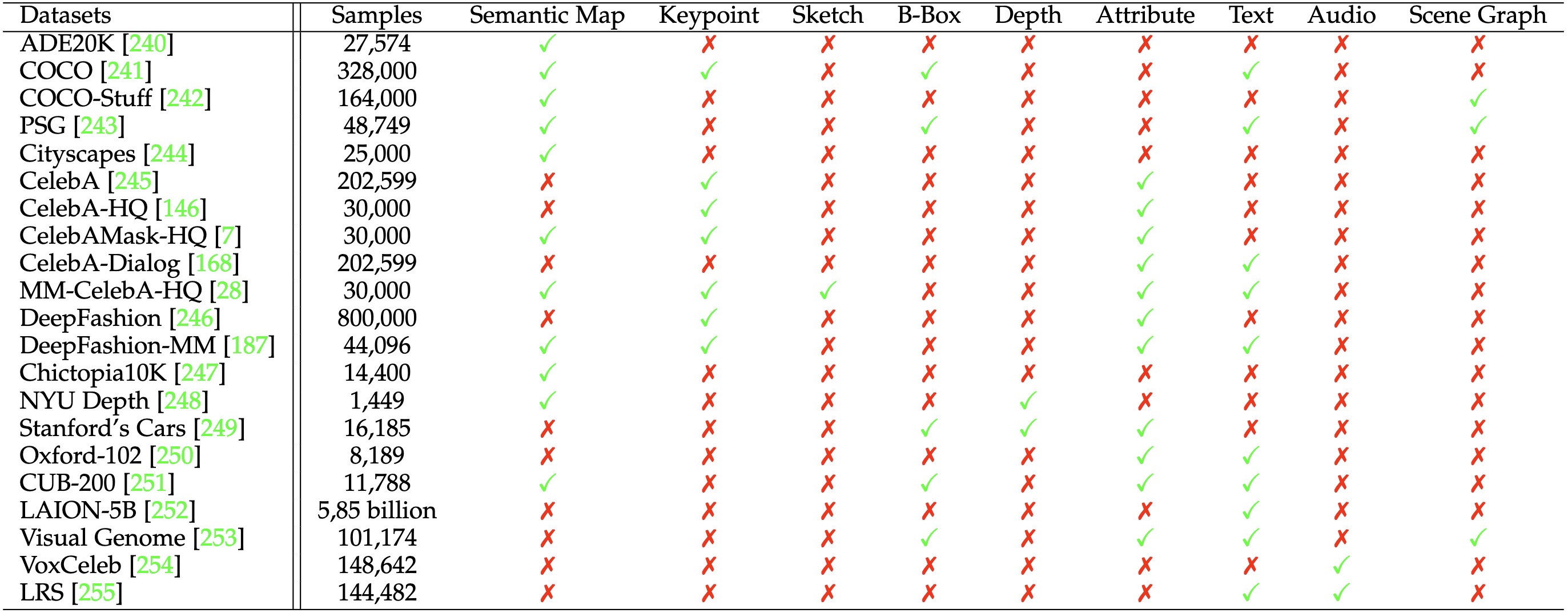
Datasets
Annotation types in popular datasets